Ollama下载安装运行模型
下载安装 Ollama
从 Ollama 官网 下载并安装;
下载安装模型
在 Ollama Library 中查找可用模型
1>. 仅下载模型
ollama pull <模型名称>
2>. 直接下载安装运行模型
ollama run <模型名称>
模型路径和迁移
模型默认的下载路径如下(可在环境变量中更改):
- 在 Windows 上,默认路径通常为 C:\Users\<用户名>\.ollama\models
- 在 Linux 上,默认的路径通常为 /usr/share/ollama/.ollama/models
1>. 从模型下载路径中将 指定模型 的整个 models 文件夹(包含 blobs 和 manifests 子文件夹)复制搬到另一台电脑的对应位置;
2>. 重启 Ollama 服务,Ollama 会自动从 默认的模型路径 中识别可用模型;
3>. 使用 ollama list 命令列出已识别的模型;
4>. 使用 ollama run <模型名称> 命令运行指定模型;
注:在模型路径中,Ollama 并没有名为模型专门命名一个文件;实际的模型是如下这样:
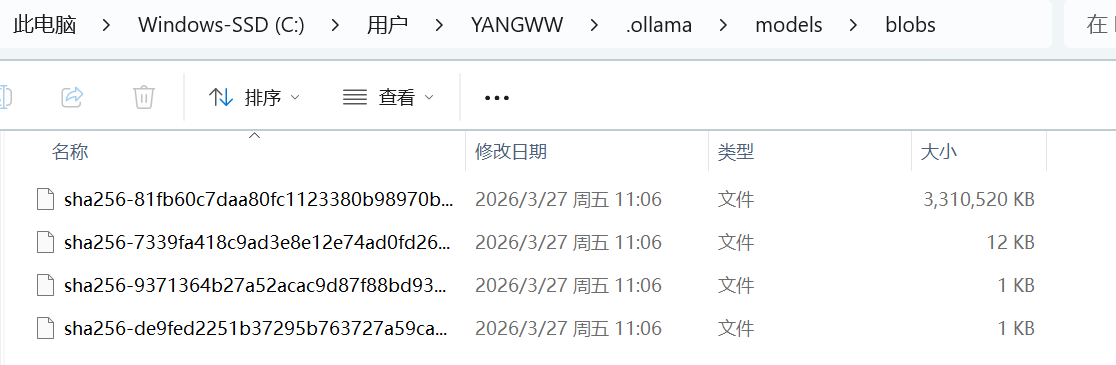
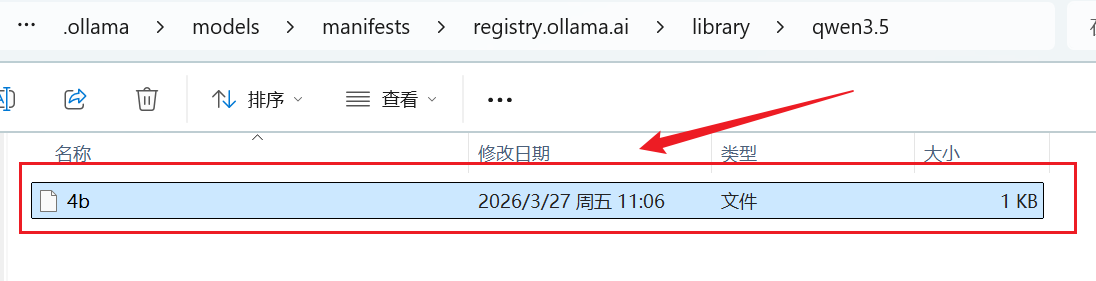
在 manifests -> registry.ollama.ai -> library -> qwen 文件中,可以查看指定对应的 blobs 文件,如下:
常用指令
ollama list:查看本地已下载的所有模型。
ollama pull <模型名称>:仅下载模型而不立即运行。
ollama rm <模型名称>:删除不再需要的本地模型以节省空间。
定制启动(指定CPU或GPU)
Ollama 在运行时,默认优先使用 GPU,如果 GPU 显存不足或不兼容,会自动回退使用 CPU;因此一般情况下,无须额外的定制启动操作。
ollama run 命令用于直接运行某个模型,ollama create 命令用于根据配置文件定制运行指定模型。Ollama 在运行时默认优先尝试使用 GPU 加速
例1:通过 CPU 运行 qwen3.5:4b 模型
1>. 新建一个文本文件,添加如下内容,并保存为 qwen-cpu.mf (如下配置是告诉 Ollama,分配给显卡的层数为 0,也就是强制全走 CPU)
FROM qwen3.5:4b PARAMETER num_gpu 0
2>. 根据配置文件定制运行
ollama create qwen3.5-cpu -f qwen-cpu.mf
例2:通过 GPU 运行 qwen3.5:4b 模型
1>. 新建一个文本文件,添加如下内容,并保存为 qwen-gpu.mf (如下配置优先走GPU)
FROM qwen3.5:4b PARAMETER num_gpu 99
2>. 根据配置文件定制运行
ollama create qwen3.5-cpu -f qwen-cpu.mf