模型参数与硬件要求
模型参数与体积
模型参数与模型体积有明确的直接关系,模型体积 ≈ 模型参数 * 2;例如:31B参数的模型,其体积通常是62GB。
如果模型是 FP32(全精度),模型体积 ≈ 模型参数 * 4,但在开源模型中 FP32(全精度)非常少见,因此可以忽略。
模型所需硬件
模型运行时要将整个模型文件加载到显存中 ,因此模型体积直接决定了所需的显存,所需显存 ≈ 模型体积 * 至少10%;例如:62GB的模型,至少需要 68.2 GB 的显存。
至少10%的显存余量是留给模型的运行开销。当然,这 10% 的余量通常只够 1-2 个人进行中等长度的对话。以 62GB 大小的模型为例如,以下是具体的显示与并发数关系:
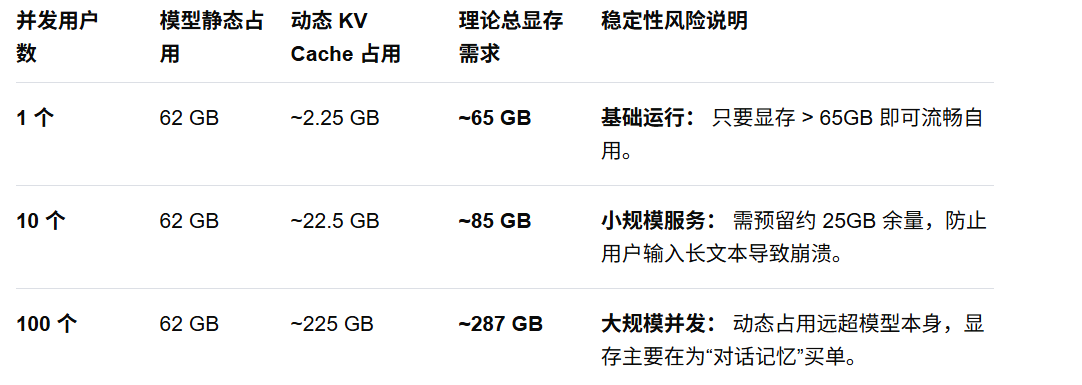
注:显存需求由 模型权重 + KV Cache + 运行开销 共同决定,且 KV Cache 是随上下文和并发动态变化的;因此以上只是通常情况下的预估,并不精确。
注:纯 CPU + 内存 运行模型时,所需内存与使用 GPU 运行时所需的显存大小是一致的。
注:模型文件(几十GB)先从磁盘 → RAM → GPU,所以内存至少要是显存的 1.2~1.5 倍;如果同时还要跑其它软件,内存就要更大;内存小于显存也许能运行,但会非常慢和卡,甚至卡死。
CPU运行
- CPU + GPU 混合运行时,速度会下降 3~10 倍;也就是显存不够,使用内存作为第二层显存。
- 纯 CPU 推理 ≈ 比 GPU 慢 10~100 倍,具体如下:

CPU + 内存之所以慢,是因为 GPU 显存带宽通常是 CPU 内存带宽的约 5~20 倍。GPU 有数千个轻量级计算核心,适合大规模数据并行;CPU 只有几十个高性能通用核心,侧重复杂控制和低延迟任务。
以 Q4 量化模型为例:
- 32B 参数模型 大概需要 20GB显存
- 72B 参数模型 大概需要 45GB 显存
- 显存大小 ≈ 模型参数 / 2 + 模型参数 * 18%
- 内存要求 ≈ 显存大小 *1.2
Qwen3.5-Plus 397B 这种级别的模型必须是使用多机分布式运行,单机跑不了。
量化版与未压缩版
模型的量化版也称压缩版,其实就是对原版模型进行压缩,以实现节约显存的目的;如下,以一个 62GB 的模型为例如:
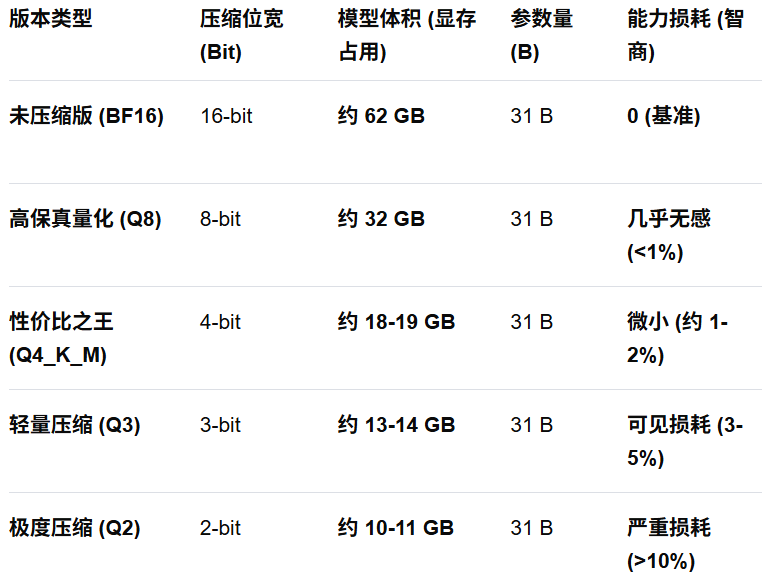
通常来说,Q4是最常用的量化版,它能将模型的体积压缩到原版的三分之一,甚至四分之一,还能保留约 98% 以上的模型能力(在简单任务接近原模型,但推理、编码、数字能力下载明显)
使用 ollama pull 模型名称 命令下载模型时,通常都下载的 Q4 量化版,因为这是社区公认的“性价比之王”。