RAG(检索增强生成)
概述
RAG(检索增强生成)是将文档资料切片后存入向量数据库中,以便 AI 模型随时调用;也就是用于构建 AI 知识库,以便 AI 在工作时随时调取。详见:https://www.youtube.com/watch?v=WWdlme1EAGI&t=2s;
理想情况下,用户期望 AI 模型天生具备“知识库”中的所有知识,以便在搜索或生成文本时能够结合知识库来增强输出,但实际上这几乎无法实现;AI模型学习知识的方式有三种:
一是将知识库放入上下文,但 AI 模型有上下文长度限制,无法放入太多知识,且这种方式很费 token ;
二是做 RAG(检索增强),这是唯一可行,且成本最低的方式;就是将知识库放入向量数据库,然后让 AI 模型在执行任务时随时查询;
三是做微调,就是将知识库通过清洗、大量标注等操作整理成高质量的训练数据,然后对模型进行微调训练;如果微调效果不佳,还需要反复迭代,人力和算力成本极高(尤其是人力)。且微调后的 AI模型并不会记住所有知识内容,它只会记住写作风格、表达方式等,并且难以更新,除非再次微调。
注:模型微调的核心价值不在于“增加新知识库”,而在于“改变模型的大脑回路”、“改为模型的言行举止(风格与格式化)”、“让模型学会特定技能”、“提升特定领域的理解力”,而非记住所有知识。
而且也不应该让 AI 模型记住所有知识,因为这会导致 AI 模型的注意力分散、生成质量下降,高质量的生成原则就是让 AI 模型只在需要时调用相关知识,这比“加载所有知识”更智能。在 AI 生成需求文档这种场景下,最佳实践是通过 模型微调 或 规则 prompt 模板工程 让模型始终遵循 固定的章节结构、表达风格,然后对知识库进行动态检索。
综上,模型的注意力是有限资源(很珍贵),无关内容会产生干扰,生成会变得模糊,模型会平均化表达;RAG 的本质是让模型只在需要时只关注正确知识,这和人类只在需要时查阅相关资料一样。因此,高质量的系统是让 AI 永远只看到“当前最相关的那几页”;知识库的组织也应该以树形结构( 目录 + 内容)来组织,即层级化索引。
无论是本地文件感知、代码补全或RAG向量数据库等,都是以层级化索引的方式来实现和组织知识;像代码补全这种场景还会进行上、下压缩等优化,详见渐进式披露。
RAG也在持续进化,最新 GraphRAG 让知识检索效率更高,详见:https://www.youtube.com/watch?v=n-lJNXemlaQ
基本原理
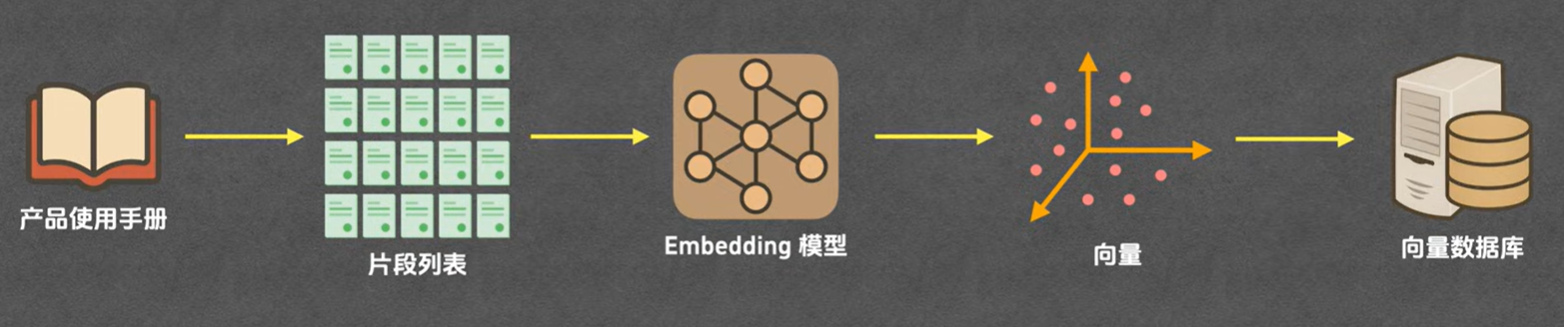
1> 知识入库
将知识文档拆成知识片段 -> 通过 Embedding 模型计算出知识片段的向量值 -> 将向量值和知识片段存入向量数据库;
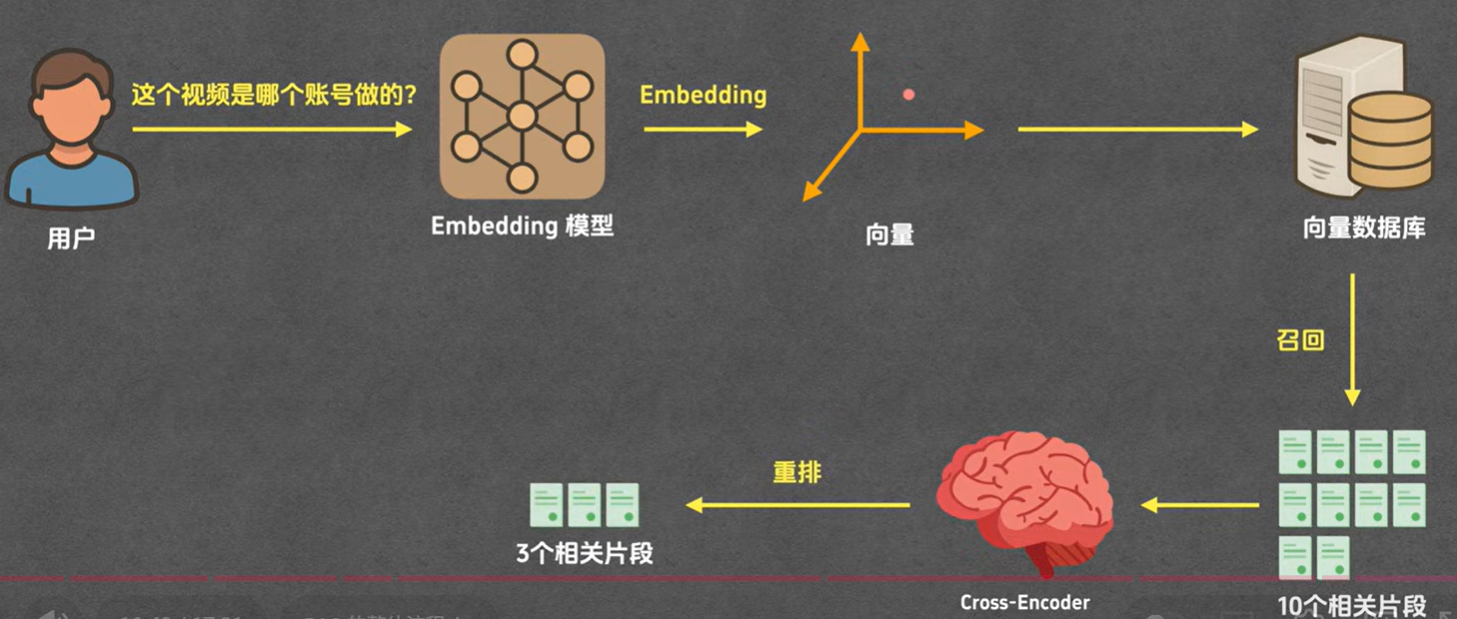
2> 用户检索知识
用户/模型 输入 -> Embedding 模型将输入转为向量值 -> 从向量数据库中检索相量值相似的多个知识片段 -> Cross-Encoder 模型从多个知识片段中筛选出相关度最高的几个知识片段 -> 返回给用户或模型;